
We Fed 34 News Articles Into an AI Prediction Engine. Here's What Actually Happened.
MiroFish claims thousands of AI agents can simulate reality and predict the future. We tested it with real geopolitical data. This is the full, unfiltered account.
Part 1: What Is The Balanced News, and Why We Ran This Experiment
Before we get into MiroFish, you need to understand what we do and why this experiment matters to us.
The Balanced News is a news intelligence platform that ingests thousands of articles daily from across the Indian and global media landscape, clusters them into stories, and layers each story with structured analytical data. We are not a news publisher. We do not write articles. We aggregate and analyze what already exists, and we give readers the tools to see through editorial spin, political framing, and selective reporting.
Every story on our platform carries a rich data envelope. Here is what a single story looks like in our system:
Story: "India's Diplomatic Engagement Over Strait of Hormuz Passage"
├── 34 source articles (from news18, indiatoday, thetribune,
│ businessstandard, firstpost, moneycontrol, and 28 others)
├── Balanced Summary (AI-generated, cross-referencing all 34 sources)
├── Political Bias Score: 0-100 scale (0 = far left, 50 = center, 100 = far right)
│ └── Per-article bias scores with reasoning
├── Sentiment Score: 54/100 (measured, factual tone)
│ └── Reasoning: "The overall tone is measured and factual, emphasizing
│ ongoing diplomatic engagement and cautious optimism..."
├── Lens Score: 29 (measures the gap between a story's importance and visibility)
├── 186 named entities with frequency counts:
│ ├── India (mentioned in 53 articles)
│ ├── Iran (52), Strait of Hormuz (52), Tehran (44)
│ ├── Petroleum (40), LPG (33), Tanker (30)
│ ├── S. Jaishankar (22), Financial Times (23)
│ ├── Donald Trump, BRICS, Abbas Araghchi, Saudi Arabia...
│ └── ...and 176 more
├── Category: Politics
├── Source diversity: 34 outlets across political spectrum
└── Related article network (each article linked to related coverage)
A few of these fields deserve explanation, because they are central to how we think about news and why we built this platform.
Political Bias Scoring
Every article that enters our system gets a political bias score on a 0-100 scale. This is not a binary "left or right" label. It is a continuous measure derived from language analysis, source attribution patterns, framing choices, and editorial tone. A score of 30 means the article leans left. A score of 70 means it leans right. A score of 50 means the language and framing are relatively neutral. We display these as L:30 C:50 R:70 so readers can immediately see where the coverage sits.
This matters because the same event gets reported very differently depending on who is doing the reporting. An article from a left-leaning outlet about Jaishankar's Hormuz diplomacy might frame it as "India cozying up to authoritarian Iran." A right-leaning outlet might frame the same event as "Strong PM Modi diplomacy secures India's energy future." Both are covering the same facts. The framing is what differs. Our bias scores make that visible.
Sentiment Analysis
Beyond political leaning, we measure the emotional tone of coverage. The Hormuz story scored 54/100 on sentiment, meaning slightly positive of neutral. The reasoning our system generated: "The overall tone is measured and factual, emphasizing ongoing diplomatic engagement and cautious optimism regarding recent progress. While acknowledging regional tensions and security risks, the coverage avoids sensationalism, focusing on official statements and practical developments like safe tanker passages and naval escorts."
This tells a reader something important: the media is not panicking about this story. Despite the geopolitical stakes, coverage is restrained. That is itself a signal worth knowing.
The Lens Score
This is our most distinctive metric. The Lens Score measures the distance between how important a story is and how much visibility it is getting. A high Lens Score means the story matters more than the coverage suggests. It surfaces stories that are being under-reported relative to their significance, using signals like coverage concentration (is only one outlet covering it?), public interest gaps (are people searching for it but not finding coverage?), power dynamics (does the story involve accountability of powerful institutions?), and structural importance (does this affect policy, markets, or public welfare at scale?).
The Hormuz story scored 29, meaning its visibility roughly matches its importance. Not buried, not overhyped. But other stories on our platform score 70, 80, even 90, meaning they are critically important and almost nobody is covering them. That is the kind of signal that no prediction engine can generate, because it requires understanding not just what happened, but what should be getting attention and is not.
Why This Data Architecture Matters
We built this because we believe the problem with news is not the lack of information. It is the lack of structure. When you read a single article about Jaishankar and Iran, you get one outlet's framing, one editorial perspective, one selection of facts. When you see the same story through our lens, with 34 sources, per-article bias scores, aggregate sentiment, entity extraction, and a Lens Score, you see the full picture. You can make your own judgments.
This is the data we fed into MiroFish. And this is why the experiment matters: we wanted to know whether a multi-agent AI simulation could extract more insight from this data than the data already provides on its own.
Part 2: The Story We Chose
The story: India's diplomatic engagement with Gulf and Iranian counterparts amid tensions over the Strait of Hormuz.
In March 2026, External Affairs Minister S. Jaishankar was engaged in a flurry of diplomatic activity with Iran, Saudi Arabia, and the UAE. The core issue: Iran had been restricting passage through the Strait of Hormuz, a chokepoint through which roughly 20% of the world's oil supply flows. India, heavily dependent on oil imports via this route, was negotiating safe passage for its tankers on a ship-by-ship basis.
Here is the balanced summary our system generated from the 34 source articles:
India has engaged in direct diplomatic talks with Iran to secure safe passage for Indian-flagged vessels through the Strait of Hormuz amid ongoing regional tensions. External Affairs Minister S Jaishankar emphasized that there is no blanket arrangement with Iran; each ship's transit is negotiated individually. Recent talks have yielded results, allowing two Indian LPG tankers to pass safely. India has denied reports of any exchange or deal involving the release of seized Iranian-linked tankers. Additionally, the Indian Navy is escorting vessels in the region to ensure their security. India has not held bilateral discussions with the US on deploying warships to the strait but continues multilateral consultations to maintain maritime safety.
We chose this story because it has everything a prediction engine should love:
- Multiple state actors with competing interests: India, Iran, Saudi Arabia, UAE, the United States, Israel, BRICS nations
- Economic variables with real-world measurability: oil prices, shipping volumes, LPG supply chains, tanker traffic
- A ticking clock: the ship-by-ship arrangement is inherently fragile and could collapse at any moment
- Military dimensions: the Indian Navy is actively escorting vessels; the US has warships in the region
- 34 source articles from outlets spanning the political spectrum, providing deep factual coverage
- 186 named entities including diplomats, heads of state, international organizations, ports, energy companies, and military assets
If you are going to test an AI prediction engine, you want a story where the stakes are high, the actors are many, the data is rich, and the outcome is genuinely uncertain. This is that story.
The Seed Document
We compiled all 34 articles into a single markdown document: 106,000 characters of raw text. This included:
- Full article content from every source (news18, indiatoday, thetribune, businessstandard, firstpost, moneycontrol, thetelegraph, and 27 others)
- Per-article metadata: source name, publication date, political bias score, sentiment score, category, location
- The balanced summary with reasoning
- All 186 entities with frequency counts
- Story-level sentiment and Lens Score
This is significantly richer input than MiroFish's example use cases (which typically involve a single report or novel excerpt). We wanted to give the engine the best possible chance to produce something meaningful.
Part 3: What Is MiroFish
MiroFish is an open-source multi-agent simulation engine that topped GitHub's global trending charts in March 2026. Built by a team backed by Shanda Group (founded by Chen Tianqiao), it describes itself as "A Simple and Universal Swarm Intelligence Engine, Predicting Anything."
The premise: you upload "seed material" (a news report, a policy document, a financial analysis), describe what you want to predict in natural language, and MiroFish does the rest. It extracts entities and relationships, builds a knowledge graph, generates AI agents with independent personas and memories, runs them through a social media simulation, and produces a prediction report based on emergent behavior.
Under the hood, MiroFish is built on the OASIS (Open Agent Social Interaction Simulations) engine from the CAMEL-AI team. It uses any OpenAI-compatible LLM (we used Gemini 2.0 Flash) and Zep Cloud for knowledge graph memory (Neo4j-backed entity extraction and relationship mapping).
The version we tested: MiroFish v1.0.2, running locally on macOS.
Part 4: The Setup
Infrastructure
- LLM: Gemini 2.0 Flash via Google's OpenAI-compatible endpoint (
https://generativelanguage.googleapis.com/v1beta/openai/) - Memory layer: Zep Cloud (free tier) providing Neo4j-backed knowledge graph construction
- Frontend: localhost:3000 (React/Vite)
- Backend: localhost:5001 (Python/Flask)
The Prediction Prompt
We entered this as our simulation requirement:
Simulate how India's diplomatic engagement with Iran, Saudi Arabia, and the UAE over safe passage through the Strait of Hormuz will evolve over the next 30 days. What public opinion trends will emerge across Indian, Iranian, and Gulf media? How will rising oil prices and US-Iran tensions affect India's energy security posture? Will Jaishankar's ship-by-ship transit arrangement hold, or will India be forced into a broader multilateral deal?
Concrete questions. Measurable outcomes. A defined time horizon. We deliberately avoided vague prompts.
Part 5: What MiroFish Did, Step by Step
Stage 1: Ontology Generation (~12 seconds)
A single LLM call analyzed our 106K-character seed document and produced a domain schema:
10 entity types generated by MiroFish:
- GovernmentOfficial — Person holding a government position (e.g. S. Jaishankar, Abbas Araghchi)
- Diplomat — Person representing a country internationally (e.g. S. Jaishankar, Chris Wright)
- MediaOutlet — Organization publishing news (e.g. Financial Times, NBC News)
- EnergyCompany — Company in energy production/distribution (e.g. Gazprom, Saudi Aramco)
- ShippingCompany — Company operating transport ships (e.g. Maersk, Evergreen Marine)
- PortAuthority — Organization managing a port (e.g. Mundra Port Authority, Kandla Port Authority)
- InternationalOrganization — Organization with international scope (e.g. BRICS, IEA)
- PoliticalAnalyst — Expert analyzing political events (e.g. Fareed Zakaria, David Ignatius)
- Person — General person entity (e.g. Narendra Modi, Donald Trump)
- Organization — General organization entity (e.g. Ministry of Foreign Affairs)
6 relationship types: REPRESENTS, REPORTS_ON, ENGAGES_WITH, IMPACTS, OPERATES_IN, COMMENTS_ON
This was genuinely impressive. In 12 seconds, the LLM produced a coherent, domain-appropriate ontology that correctly identified the key actor categories in a complex geopolitical story. The entity types map cleanly to the real-world structure of the situation. The relationship types capture the essential dynamics.
Stage 2: Knowledge Graph Construction (~20 minutes)
The 106K-character seed was chunked into 301 pieces (500 characters each, 50-character overlap) and sent to Zep Cloud for entity extraction. Each chunk got an LLM call to identify entities and relationships against the ontology schema.
The result: a Neo4j knowledge graph with nodes for every significant actor, location, organization, and concept in the story, connected by typed edges representing their relationships. Clicking on any node shows its summary and connections.
For example, clicking the "Kandla" node reveals: "The Indian tanker Shivala is expected to reach Kandla today. India has the Port of Kandla. The vessel Honda Iris is transporting liquefied petroleum gas (LPG) to the port of Kandla."
Clicking "Indonesia" surfaces something less obvious: Indonesia had commented on the situation, "highlighting global concern for energy security and peaceful resolution regarding the importance of India-Iran dialogue for Strait of Hormuz stability."
This is useful. The knowledge graph surfaced a peripheral actor (Indonesia) and its stance on the situation, which was buried across the 34 source articles and not immediately obvious from reading any single one. This is genuine value extraction.
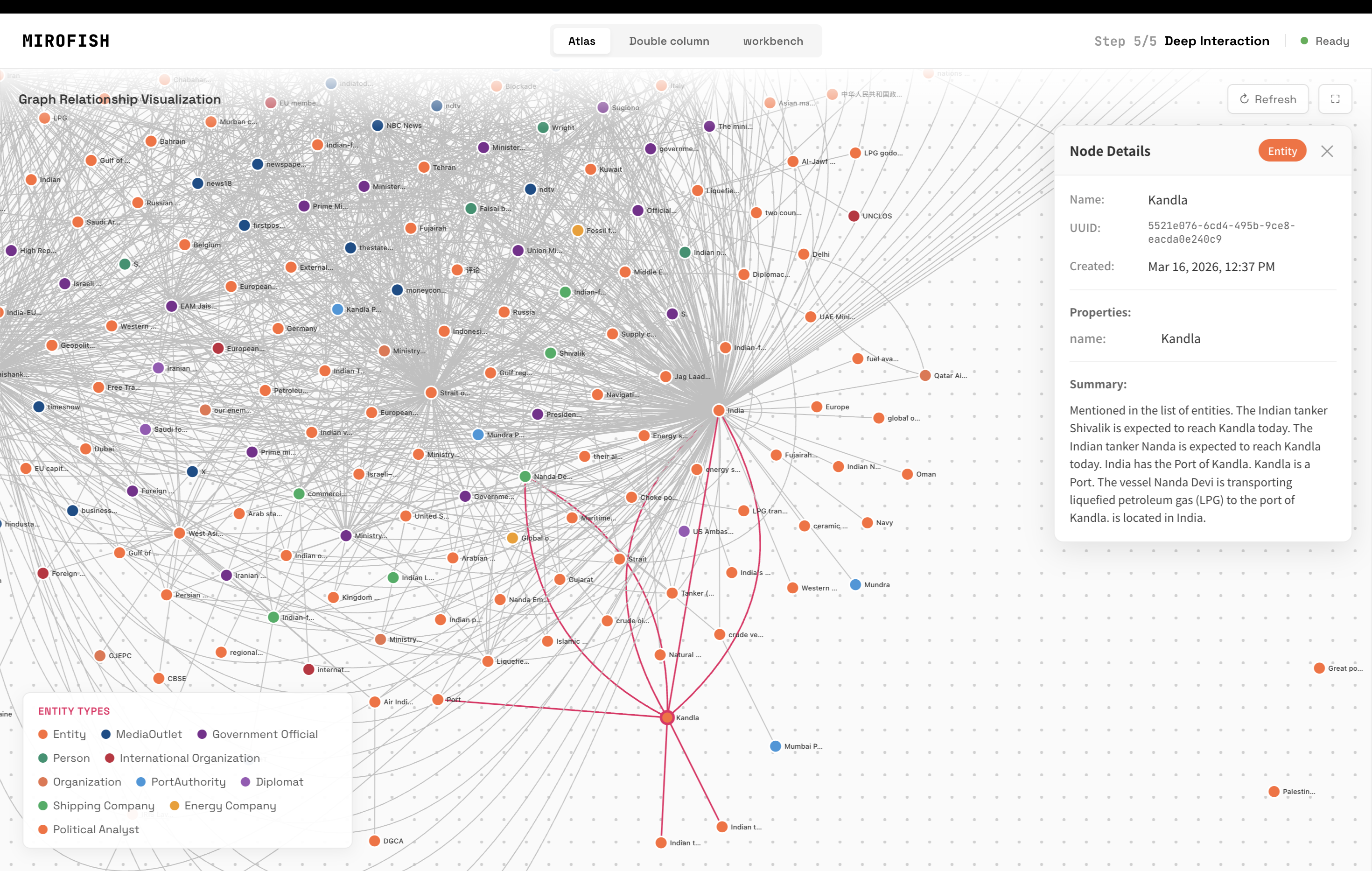 The knowledge graph with the Kandla port node selected, showing connections to Indian tankers, LPG shipments, and shipping routes extracted from 34 source articles.
The knowledge graph with the Kandla port node selected, showing connections to Indian tankers, LPG shipments, and shipping routes extracted from 34 source articles.
 The graph surfaced peripheral actors like Indonesia, whose comments on Hormuz energy security were distributed across multiple articles and easy to miss.
The graph surfaced peripheral actors like Indonesia, whose comments on Hormuz energy security were distributed across multiple articles and easy to miss.
Stage 3: Agent Generation
MiroFish spawned 56 agents from the knowledge graph. Each agent received: - A persona profile derived from its entity type - Personality traits and behavioral tendencies - Political leanings calibrated to the entity - Knowledge from the knowledge graph subgraph relevant to that entity
The cast included simulated versions of real entities: NBC News, Firstpost, India Today, the German Foreign Minister, port authorities, energy companies, political analysts, and government officials from India, Iran, Saudi Arabia, and the UAE.
The agents were configured to interact across two simulated social media platforms: a fake Twitter and a fake Reddit. The theory behind dual-platform simulation is that short-form media (Twitter) and long-form media (Reddit) produce different opinion dynamics for the same event. Hot takes spread differently than threaded discussions. Running both in parallel lets you compare how narratives diverge across platform types.
Stage 4: Simulation (~8 minutes)
We set the simulation to 40 rounds (reduced from the default 720, on MiroFish's own recommendation for first-time runs). Each round represented 18 hours of real-world time, covering the full 30-day prediction window.
Over 40 rounds, the 56 agents autonomously posted, replied, retweeted, upvoted, commented, and argued. The simulation ran both the Twitter and Reddit platforms simultaneously.
Final numbers: - 40 rounds completed - 295 Twitter actions (posts, replies, retweets, likes) - 275 Reddit actions (posts, comments, upvotes, downvotes) - 570 total agent interactions - Runtime: approximately 8 minutes - Estimated token consumption: ~4.5 million tokens on Gemini Flash
Stage 5: Report Generation and Agent Interviews
After the simulation completed, MiroFish's ReportAgent analyzed all 570 interactions, identified patterns and trends, and conducted structured interviews with 10 selected agents. Each agent was asked 5 questions about diplomatic outlook, energy security, media trends, and whether the ship-by-ship arrangement would hold.
The output: a structured prediction report titled "India's Strait of Hormuz Navigation: A 30-Day Forecast."
Part 6: The Output
The report contained three sections:
Section 1: India-Iran Diplomacy, A Ship-by-Ship Approach
The simulation concluded that India's ship-by-ship transit arrangement works short-term but is fragile. Key findings: - Iran cooperates partly to demonstrate regional stability and counter US isolation - The arrangement's effectiveness depends heavily on Iran's continued cooperation and regional stability - If the arrangement cannot be sustained, India may be forced to consider broader multilateral agreements involving Saudi Arabia, UAE, or even the US - But any security agreement involving the US could anger Iran and further escalate tensions
Simulated agent quotes included: "India's Foreign Ministry is closely cooperating with Iran to ensure every Indian oil tanker can safely pass through the Strait of Hormuz" and "This arrangement could be exploited by the US to further strengthen its military presence in Hormuz."
Section 2: Media Narratives and Public Opinion
The simulation predicted divergent media framing across regions: - Indian media would focus on oil price impact on the domestic economy - Iranian media would emphasize external pressures on Iran's economy - Gulf media would track energy revenue gains while worrying about geopolitical risk - Domestic Indian opinion would split between pragmatists supporting the deal and critics worried about diplomatic image
Section 3: Energy Security Under Pressure
India faces severe energy security pressure. The simulation suggested India would pursue diversification: renewable investment, strategic oil reserves, dialogue with Russia for alternate supply, and increased domestic exploration.
The Deep Interaction
After the report, MiroFish offers a "Deep Interaction" mode where you can chat directly with any of the 56 agents. We tested this by asking the simulation: "How much higher/lower will oil prices go in the next 30 days?"
The response: "The provided report does not contain specific predictions about the exact increase or decrease in oil prices over the next 30 days. It only mentions that rising oil prices are a factor impacting India's energy security."
We then asked: "And do you mean by security? What's energy security?"
The agent began explaining the concept of energy security in general terms.
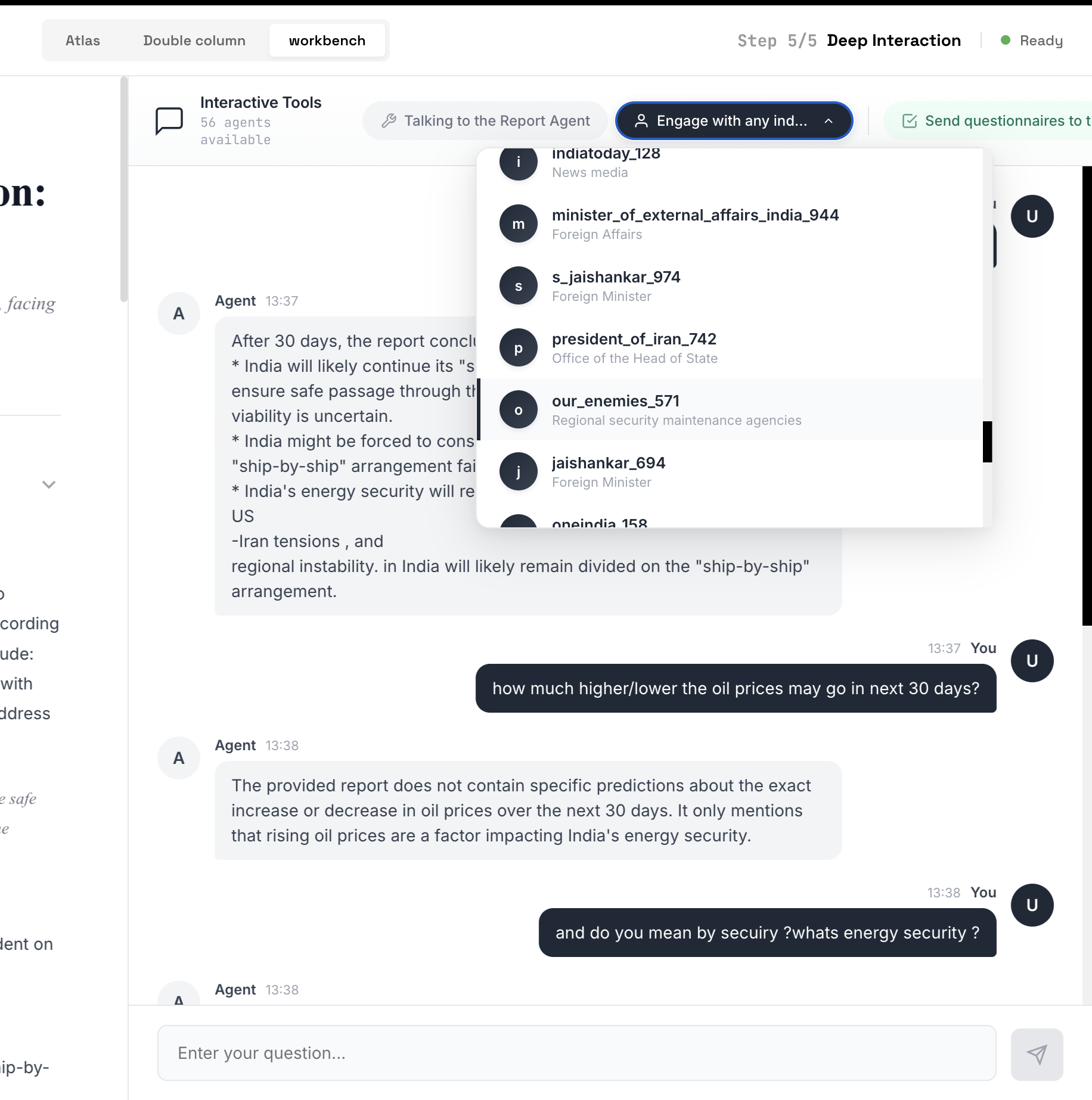 We asked MiroFish's agents a concrete question about oil prices. The system admitted it could not provide specific predictions. The dropdown shows the 56 available agents including simulated versions of India Today, the Indian External Affairs Minister, Iran's President, and others.
We asked MiroFish's agents a concrete question about oil prices. The system admitted it could not provide specific predictions. The dropdown shows the 56 available agents including simulated versions of India Today, the Indian External Affairs Minister, Iran's President, and others.
Part 7: The Honest Verdict
Let us be direct: the report told us nothing we did not already know from reading the 34 source articles.
Every prediction was hedged into meaninglessness: - "Oil prices could rise further if tensions escalate" - "The ship-by-ship arrangement may or may not hold" - "India might need to consider multilateral agreements" - "Public opinion is divided"
We asked concrete questions: Will the arrangement hold? How will oil prices move? Are we heading toward broader conflict? When does normalcy return? We got the geopolitical equivalent of "it depends."
No probability estimates. No timelines. No scenario branching with confidence intervals. No concrete predictions that could be validated against future reality. When we directly asked for a specific oil price forecast, the system admitted it could not provide one.
The balanced summary that our own system generated from those same 34 articles, without any simulation, without 56 agents, without 570 social media interactions, was more informative. It clearly stated: there is no blanket arrangement, each ship is negotiated individually, two LPG tankers have passed safely, India has denied reports of any exchange deal, and the Navy is escorting vessels. Those are facts. They are specific. They are verifiable.
The MiroFish report restated those same facts, wrapped them in simulated agent quotes, and presented them as "predictions." The simulation added volume, not insight.
Part 8: Why Multi-Agent LLM Simulation Cannot Predict the Future
This is not a criticism of MiroFish specifically. The MiroFish team has built a genuinely well-engineered system. The ontology generation is fast and accurate. The knowledge graph construction surfaces non-obvious connections. The dual-platform simulation architecture is a clever research concept. The codebase, for a v0.1.0 open-source project, is clean and well-structured.
The problem is more fundamental. Using large language models as the cognitive engine for prediction agents is a category error.
The Echo Chamber Problem
When you run 56 agents powered by the same underlying LLM (in our case, Gemini 2.0 Flash), you are not getting 56 independent perspectives. You are getting 56 variations of the same model's output distribution. The "swarm intelligence" that MiroFish promises requires genuine cognitive diversity, where independent reasoners arrive at different conclusions through different reasoning processes, and the aggregate of their disagreements produces insight.
What happens instead: all 56 agents arrive at roughly the same hedged, balanced, non-committal analysis. They do this because they are all instances of the same neural network, trained on the same data, exhibiting the same tendency toward safe, consensus-oriented output. The persona overlays (GovernmentOfficial vs. MediaOutlet vs. PoliticalAnalyst) change the style of the output but not the substance. An agent labeled "Iranian Foreign Minister" produces slightly different language than one labeled "Financial Times," but both reach the same conclusions.
This is not swarm intelligence. It is an echo chamber with extra steps.
The Narrative-Prediction Confusion
Language models are extraordinarily good at generating text that sounds like analysis. They can adopt personas, cite evidence, structure arguments, weigh tradeoffs, and reach conclusions. The output reads like a think tank report. But there is a fundamental difference between generating plausible-sounding narrative and making actual predictions.
Prediction requires: - Specificity: "Oil will hit $95/barrel within 14 days" vs. "oil prices could rise" - Falsifiability: the prediction must be wrong in a way that can be observed - Calibration: the system must have a track record of being right X% of the time when it says X% - Skin in the game: prediction markets work because people bet real money; forecasting tournaments work because accuracy is measured and ranked
MiroFish produces none of these. Its output is sophisticated commentary dressed as forecasting. The very sophistication of the output, the detailed reports with agent-level quotes, the structured sections, the simulated media dynamics, makes it harder to evaluate, because it looks like deep analysis while saying nothing falsifiable.
The Missing Inputs
Real geopolitical forecasting incorporates data that LLMs simply do not have access to: - Oil futures and commodities markets: real-time pricing, options flow, OPEC production data - Shipping traffic data: AIS vessel tracking, port throughput statistics, insurance rates for Hormuz transit - Military intelligence: satellite imagery of naval deployments, signals intelligence, defense ministry communications - Economic indicators: forex movements, trade balance data, refinery capacity utilization - Human intelligence: what diplomats are actually saying in private, what backchannel negotiations are underway
An LLM agent roleplaying as the Iranian Foreign Minister does not have access to what the actual Iranian Foreign Minister is thinking, planning, or negotiating behind closed doors. The agent can only generate text that is statistically consistent with what an Iranian Foreign Minister might publicly say based on the LLM's training data. That is not prediction. That is sophisticated impersonation.
No Benchmarks, No Accountability
As of March 2026, MiroFish has published zero benchmarks comparing its predictions against actual outcomes. The demos on their GitHub (a Wuhan University public opinion simulation, a Dream of the Red Chamber novel ending) are illustrative, not validating. There is no track record. There is no calibration data. There is no way to assess whether the system's predictions are better than chance, better than a single informed human, or better than simply reading the source articles.
This is the single biggest red flag. Any system that claims to predict the future should be measured against reality. Without that measurement, the claim is unfalsifiable, and unfalsifiable claims are not predictions. They are narratives.
Part 9: What We Learned
What MiroFish Does Well (and What Others Can Learn From)
Despite our skepticism about the prediction claims, MiroFish contains genuinely valuable components:
1. Automated Ontology Generation Extracting a coherent domain schema from 106K characters of unstructured text in 12 seconds is a useful capability far beyond prediction. This could be applied to knowledge management, document analysis, legal discovery, research synthesis, and dozens of other domains where you need to quickly understand the entity structure of a large text corpus.
2. Knowledge Graph Construction The Zep-powered entity extraction and Neo4j graph construction surfaced connections we had not noticed in our own data. Indonesia's commentary on the Hormuz situation, for example, was distributed across multiple articles and easy to miss. The graph made it visible. This is real value, and it is the kind of capability that could enhance our own analytics pipeline at The Balanced News.
3. Dual-Platform Simulation Architecture The idea of comparing how the same information propagates differently on short-form vs. long-form platforms is a legitimate research question with applications in media studies, misinformation research, and communication strategy. The architecture to run these simulations in parallel is well-designed.
4. Clean Engineering For a v0.1.0 project, MiroFish is well-built. The five-stage pipeline (ontology, graph, agents, simulation, report) is logical and modular. The API design is clean. The frontend provides meaningful visualization of the knowledge graph. The team clearly knows how to build software.
What the Experiment Taught Us About Our Own Data
Running this experiment reinforced something we already believed but had not stress-tested: structured, well-annotated real-world data is more valuable than simulated data, no matter how sophisticated the simulation.
Our 34 articles with per-source bias scores, aggregate sentiment, entity extraction, and Lens Score contain more actionable intelligence about the Hormuz situation than 570 simulated social media posts generated by AI agents. Not because our system is smarter, but because our data comes from real journalists talking to real sources with real access to information that no LLM can simulate.
The balanced summary our system generated, without any simulation, clearly identified the key facts: no blanket arrangement exists, each ship is negotiated individually, two tankers have passed safely, India denies any exchange deal, the Navy is escorting vessels. These are specific, verifiable, and useful. The MiroFish report restated these same facts but added no new information.
Part 10: Conclusion
We want to be clear about what this piece is and is not.
This is not an attack on MiroFish. The team behind it has built an impressive piece of engineering. The ontology generation is fast and accurate. The knowledge graph surfaces non-obvious connections. The simulation architecture is thoughtfully designed. The open-source contribution is valuable. Building something that tops GitHub's global trending charts and attracts investment from Shanda Group is a genuine achievement. We respect what they have built.
What this piece is about is a broader question: can multi-agent LLM simulation predict the future?
Based on our experiment, the answer is no. Not because the technology is bad, but because the approach has a fundamental limitation. Language models generate text that is statistically consistent with their training data. When you run 56 of them in a simulation, you get 56 statistically consistent outputs. The aggregate does not produce emergence, insight, or genuine prediction. It produces volume.
The output sounds impressive. It reads like expert analysis. It is structured, well-reasoned, and articulate. But it says nothing that could not be derived from reading the source material directly, and it says nothing specific enough to be proven right or wrong. That is the definition of unfalsifiable commentary, and unfalsifiable commentary is not prediction, no matter how many agents produce it.
Multi-agent simulation for predicting the future sounds extraordinary on paper. The pitch is compelling: simulate reality, rehearse the future, win decisions before they happen. But in practice, when you feed it real geopolitical data with real stakes, the output collapses into the same hedged, balanced, non-committal analysis that a single LLM call would produce. The simulation adds cost and complexity without adding insight.
For anyone evaluating tools like MiroFish for real-world decision-making, we would suggest: - Use prediction markets (Polymarket, Metaculus) for calibrated probability estimates from people with skin in the game - Use quantitative models fed with real economic, military, and shipping data for scenario analysis - Use superforecasting methodologies (as developed by Philip Tetlock) for structured human judgment with accountability - Use MiroFish's knowledge graph capabilities (genuinely useful) separately from its prediction claims - Read the actual journalism. 34 articles from reporters with sources on the ground will always contain more signal than 570 simulated social media posts
We will continue to experiment with multi-agent systems. The knowledge graph and ontology capabilities have real potential for enhancing our analytics at The Balanced News. But for prediction, we will rely on what has always worked: real data, real sources, and the intellectual honesty to say "we don't know" when we don't know.
The future is not a simulation. It is not an echo chamber of language models agreeing with each other in slightly different voices. It is messy, surprising, and driven by information that no model has access to. The best we can do is give people the clearest possible view of what is happening right now, from as many perspectives as possible, with as much analytical structure as we can provide.
That is what The Balanced News does. And after running this experiment, we are more convinced than ever that it matters.
This evaluation was conducted by The Balanced News team in March 2026 using MiroFish v1.0.2 with Gemini 2.0 Flash and Zep Cloud. The full Hormuz story with all 34 source articles is available on The Balanced News. MiroFish is open-source and available at github.com/666ghj/MiroFish.
We thank the MiroFish team for their open-source contribution to the multi-agent simulation space. This evaluation is based on a single experiment with a single story and should be read as one data point, not a definitive judgment on the technology's potential.


